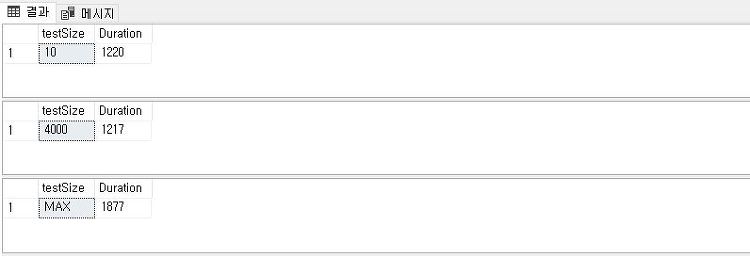
VARCHAR(MAX) 와 NVARCHAR(MAX) 의 단점VARCHAR 와 NVARCHAR 는 유니코드 라는 점에서 다르기 때문에 VARCHAR 로 설명하겠습니다. VARCHAR(N) 컬럼에 데이터를 저장할 때에는 물리적으로 같은 방식으로 저장됩니다.이 말은, 어떤 특정한 동작없이 블록에 바로 쓰인다는 말을 뜻합니다. 그러나 VARCHAR(MAX) 컬럼에 저장하는 경우에는 TEXT 타입처럼 다뤄지게 됩니다.이는 저장을 위한 추가적인 절차가 필요하다는 뜻입니다. ( 단, 저장되는 데이터길이가 8000 자 이상인 경우 ) 왜 8000 자 이상인가? 8K 블록에는 최대 8000 자를 저장할 수 있으며, 이를 넘어가게 되는 경우 오버플로우가 발생하게 됩니다.out of row 라고 말하며, 이를 저장하기 위해..
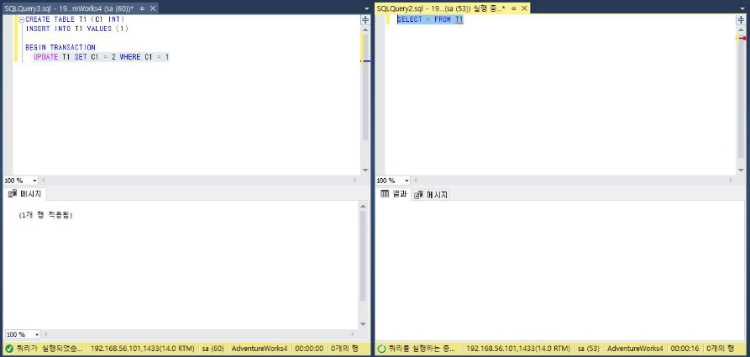
WITH(NOLOCK)SQL Server 에서 WITH(NOLOCK) 의 힌트를 제공합니다. WITH(NOLOCK) 의 의미는 다음과 같습니다.락이 잡혀있는 데이터에 접근하여 데이터를 읽는다.락이 잡혀있다는 말은 트랜잭션 중이라는 의미이고, 트랜잭션 내에서 데이터는 변경된 데이터를 읽습니다.즉 잠금을 무시한 Dirty Read 이며 트랜잭션이 Rollback 되는 경우에는 잘못된 데이터를 읽을 수 있게 됩니다. 그럼에도 불구하고 WITH(NOLOCK) 옵션은 SELECT 가 대기해야 하는 불상사를 막을 수 있기 때문에 자주 사용됩니다. WITH(NOLOCK) 테스트WITH(NOLOCK) 이 없는 일반 구문을 사용하는 경우,C1 = 1 의 데이터에 대해서 LOCK 이 잡혀있기 때문에 SELECT 는 대기하..
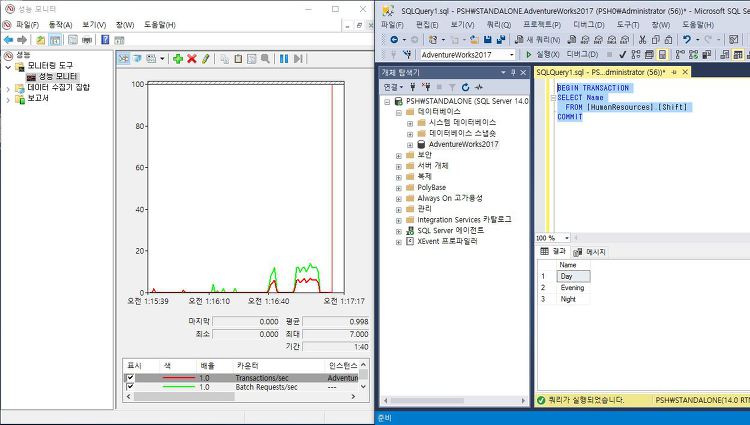
SQL Server 의 Batch Request 와 Transaction 의 모니터링 이유SQL Server 를 유지 관리 할 때에는 현재 서버가 얼마나 열일(?)하는지에 대한 척도를 알고 있어야 합니다.위 2개의 지표는 이러한 개념을 알게 해주는 지표가 될 수 있습니다.2개의 지표는 비슷하게 보일 수 있지만 측정 시 다른 유형의 시작점을 사용하고 있기 때문에 차이점을 알아야 합니다. SQL Server 배치여러 SQL 문을 명령문 그룹으로 실행하거나,여러 SQL 문 그룹으로 구성된 단일 SQL 문을 실행하는 경우 SQL Server 의 일괄 처리로 간주됩니다.이는 실질적으로 전체 일괄 처리 문의 실행 후에 결과가 반환된다는 것을 의미합니다. 대부분의 경우 네트워크 트래픽을 감소시킬 수 있으며, 대상 데..
CheckPoint 란 ( 데이터베이스 검사점 )CheckPoint 란 SQL Server 데이터베이스 엔진이 예기치 않은 종료 또는 충돌 후 복구과정에서 로그에 포함된 변경 내용의 적용을 시작할 수 있는 알려진 올바른 지점을 만드는 것을 의미합니다. 성능상의 이유로 SQL Server 는 변경이 있을 때마다 메모리에서 페이지를 수정하며 이러한 페이지를 실시간으로 디스크에 기록하지 않습니다.대신 SQL Server CheckPoint 는 메모리 상의 Dirty 된 페이지와 메모리의 트랜잭션 로그 정보들을 디스크로 동기화 하는 작업을 정기적으로 수행합니다. 이러한 작업은 위에서 말했던 것처럼 복구 시간을 단축하기 입니다. CheckPoint 설정 종류 속성 구문 설명 자동 EXEC sp_configure ..
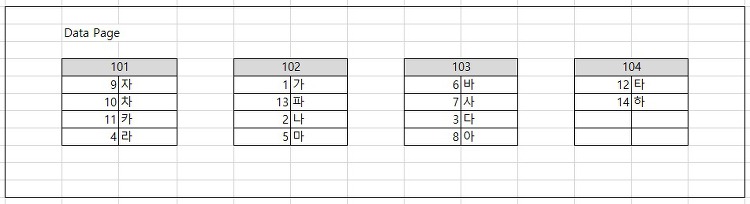
인덱스인덱스는 데이터를 빠르게 검색할 수 있게 해주는 객체입니다.컬럼을 오름차순 혹은 내림차순으로 정렬한 후에 빠르게 찾을 수 있도록 도와줍니다. 책의 색인을 의미하죠. 그렇다고 인덱스를 무작정 생성하는 것도 좋은 방법은 아닙니다.인덱스를 만들게 되면 인덱스를 위한 디스크 공간이 필요하며, 인덱스가 있는 테이블은 DML 작업 시 더 많은 비용과 시간을 필요로 하기 때문입니다. 이러한 이유로 인해서 인덱스를 만들 때 해당 테이블의 용도를 정확히 이해한 후에,적절한 컬럼으로 Clustered Index 와 Non Clustered Index를 구성해야 합니다. 인덱스를 만드는 과정데이터페이지를 인덱스 키 값으로 정렬을 한 후 리프레벨부터 인덱스페이지를 만들어 갑니다.인덱스페이지가 다 차게 되면 새로운 인덱스..
인덱스의 종류SQL Server 에서는 인덱스의 종류로 크게 Clustered Index 와 Non Clustered Index 를 지원합니다.Clustered Index 는 해당 키를 기준으로 물리적으로 정렬되어지는,Non Clustered Index 는 해당 키를 기준으로 논리적으로 정렬되어 지게 됩니다. SQL Server 에 Primary Key 를 생성하는 경우 기본적으로는 Clustered Index 로 생성됩니다.그러나 Primary Key 를 Non Clustered Index 로 생성한 후 Clustered Index 를 다른 컬럼으로도 생성할 수 있습니다. Clustered Index 는 가장 좋은 성능을 발휘하지만 테이블에서 한개밖에 생성할 수 없기 때문에,해당 테이블을 조회하는 쿼리..
문제 원인제목에 나와있다 시피 Ad Hoc Distirbute Queries 기능이 비활성화 되어 있기 때문입니다. 해결 방법SP_CONFIGURE 프로시저로 Ad Hoc 옵션을 활성화 시켜줍니다.한문장씩 실행하는걸 권장드립니다.EXEC SP_CONFIGURE 'show advanced options', 1;RECONFIGUREGO EXEC SP_CONFIGURE 'Ad Hoc Distributed Queries', 1;RECONFIGUREGO 이후에 다시 쿼리를 실행하는 경우 정상적으로 데이터를 가져오는 것을 볼 수 있습니다.
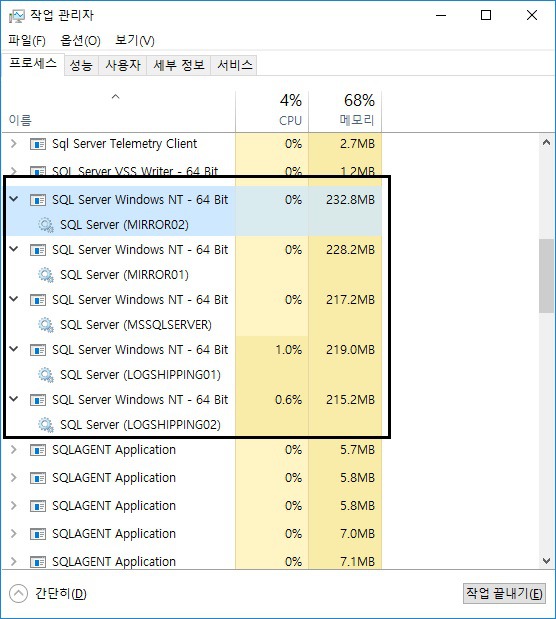
인스턴스데이터베이스 관점에서의 인스턴스는 쉽게 생각해서 하나의 데이터베이스 관리 시스템을 의미합니다.SQL Server 는 단일 서버에서 멀티 인스턴스를 지원합니다.즉, 하나의 물리적인 서버에서 둘 이상의 데이터베이스 관리 시스템을 운영할 수 있습니다. SqlServr.exeSQL Server는 SQLServr.exe 프로세스에 의해 실행됩니다.SQLServr.exe 는 하나의 데이터베이스 관리 시스템을 의미한다고 볼 수 있으며,데이터베이스가 사용하는 메모리, 각각의 데이터베이스, 데이터베이스를 운영하기 위한 여러 프로세스와 도구들이 연계됩니다.이러한 데이터베이스가 운영되는 단위를 SQL Server 에서는 인스턴스 라고 부릅니다. 아래 사진과 같이 하나의 물리적 서버에서 여러개의 SqlServr.exe..
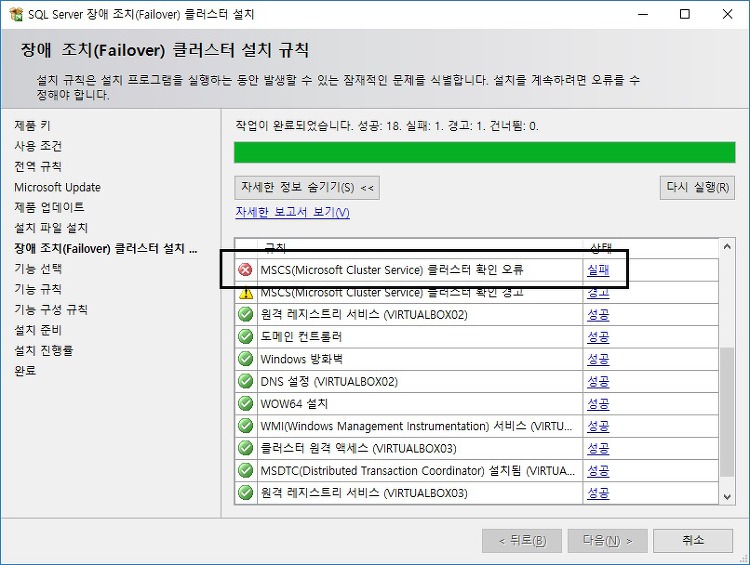
MSCS ( Microsoft Cluster Service ) 클러스터 확인 오류MSSQL Failover Cluster 를 설치하는 도중 아래와 같은 오류가 발생했습니다. 에러 로그를 좀더 자세히 찾아보니, Cluster_VerifyForErrors 라는 오류로 나오네요. 오류 해결이 방법은 꼼수입니다. CMD 창에서 해당 경로애소 설치프로그램을 실행할때 오류를 체크하지 않겠다는 옵션을 부여합니다.원칙대로라면 위의 에러를 제대로 해결하고 가야하겠죠. SETUP.EXE /SkipRules=Cluster_VerifyForErrors /Action=InstallFailoverCluster 이번에는 오류가 발생하지 않은 것을 확인할 수 있습니다.
CROSS APPLY 란, 그리고 OUTER APPLY 란table-valued expression 이 사용가능한 조인 방법을 의미합니다. table-valued expression 은 함수에서 RETURN 타입이 테이블 형태인 경우를 의미합니다. 테스트는 아래의 2개 테이블과 1개의 함수로 진행해 보겠습니다.함수의 내용을 보게되면 결국 매개인자로 테이블의 데이터를 반환한다 라는 것을 확인할 수 있습니다.CREATE TABLE FIRST_TABLE (C1 INT, C2 INT)INSERT INTO FIRST_TABLE VALUES (1, 1), (2, 2), (3, 3), (4, 4), (5, 5)GO CREATE TABLE SECOND_TABLE (C1 INT, C2 INT)INSERT INTO SEC..