오라클은 다중 테이블을 조인하여 데이터를 갱신하는 기능을 지원합니다. T1 테이블 A1, A2, A3 컬럼, T2 테이블 B1, B2, B3 컬럼에서 A2 와 B2 의 데이터가 같고 A1 의 데이터가 1 인경우 A3 을 B3 으로 업데이트 한다고 합니다.CREATE TABLE A ( A1 INT, A2 INT, A3 INT ); CREATE TABLE B ( B1 INT, B2 INT, B3 INT ); INSERT INTO A VALUES (1, 3, 3); INSERT INTO B VALUES (1, 3, 5); COMMIT;UPDATE 문은 다음과 같이 작성할 수 있습니다.UPDATE A SET A3 = ( SELECT B3 FROM B WHERE A.A2 = B.B2 AND A.A1 = 1 );이..
Database/Oracle

SQL 의 성능은 시스템 운영에 매우 중요합니다.예를들어 사용자가 평소 1초내로 응답받던 결과가, 갑자기 느려지면 사용자는 그 서비스를 더이상 사용하지 않을수도 있습니다. 이번 포스팅은 SPM(SQL Plan Management 실행계획 관리) 을 통해 SQL 성능이 갑자기 느려졌을 때, 대처하는 방법입니다. SPM 을 관리함으로써 아래와 같은 효과를 얻을 수 있습니다. - 성능 안정화 - 성능 개선 먼저 SPM 아키텍처에 대해 알아봅니다.SPM 은 SQL 성능이 저하될 경우를 대비해 미리 실행계획을 저장합니다.이렇게 저장된 실행계획은 'SQL 계획 베이스라인' 이라고 불립니다.실행계획은 SQL 단위로 다수개가 저장될 수 있습니다. SPM 은 SQL 관리 베이스라는 딕셔너리 뷰에서 관리되며, SYSAUX..
ORACLE 은 대량의 레코드 적재를 FORALL 키워드 를 이용하여, 벌크로 적재하는 기능을 제공합니다.또한 이런 기능을 BULK INSERT 라고 칭합니다. 벌크 INSERT 는 레코드를 배열의 값에 저장하고 한번에 INSERT 하는 작업을 수행합니다. 예를들어서 테이블이 아래와 같은 경우,CREATE TABLE MOZI ( C1 NUMBER, C2 NUMBER ); 레코드를 3건 넣기 위해서는 INSERT 구문을 3번 수행해야 합니다.SQL> INSERT INTO MOZI VALUES (1, 1); SQL> INSERT INTO MOZI VALUES (2, 2); SQL> INSERT INTO MOZI VALUES (3, 3); SQL> COMMIT; 반면, FORALL 을 사용하여 데이터를 배열에..
ORACLE 은 SQL 을 병렬 힌트를 부여하여 실행하는 기능을 제공합니다.이 기능을 사용하면 어플리케이션 쪽에서 소스를 수정하지 않아도 되므로, 많은 이점이 있습니다. 병렬 힌트란, 데이터를 가져오는 작업을 단일이 아닌 멀티로 진행하여 빠른 응답을 제공받습니다. 병렬 쿼리 사용 방법먼저, 병렬처리가 가능하도록 세션에 권한을 부여합니다.SQL> ALTER SESSION ENABLE PARALLEL DML; Session altered.병렬 쿼리는 PARALLEL 힌트를 사용하여 활성화 합니다. 괄호안의 수는 멀티 작업 스레드를 의미합니다.SQL> SELECT /*+ PARALLEL (4) */ 2 C1, C2 3 FROM 4 MOZI; C1 C2 ---------- ---------- 1 1 2 2 병렬..
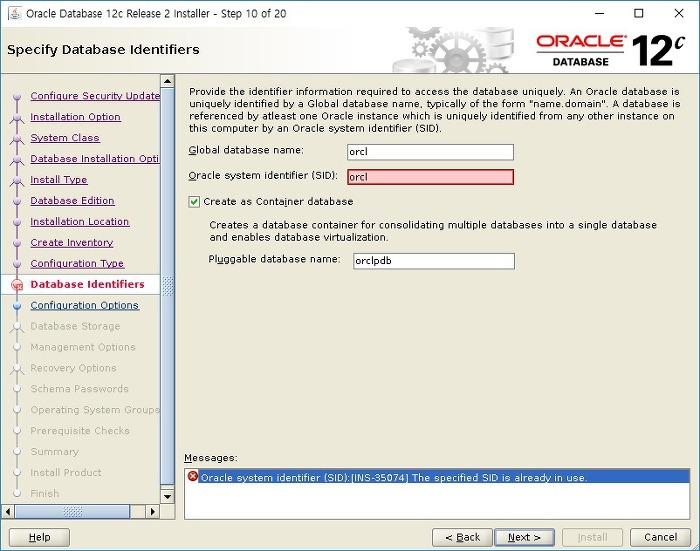
오라클 설치시 SID 가 이미 존재한다는 오류와 함께 설치가 진행되지 않은 경우가 있습니다. 이때에는 /etc/ 경로의 oratab 파일을 삭제한 뒤 다시 설치를 진행하면 됩니다.# cd /etc # rm oratab rm: remove 일반 파일 `oratab'? y
TEST 명으로 된 계정 혹은 롤이 없는 상황에서ORACLE 에 TEST 계정을 생성하려고 하는데 아래와 같은 오류가 나왔습니다. ORA-65096: invalid common user or role name SQL> drop user test; drop user test * ERROR at line 1: ORA-01918: user 'TEST' does not exist SQL> drop role test; drop role test * ERROR at line 1: ORA-01919: role 'TEST' does not existSQL> create user test identified by test; create user test identified by test * ERROR at line 1:..
이전 포스팅에서 나온 오류를 해결 한 후, 계속해서 프로그램을 짜던 중아래와 같은 에러코드를 다시한번 뱉습니다.[ERROR] Insert Execute Failure! SQLCODE : -1001 ERROR MSG : ORA-01001: invalid cursor 오라클 공식문서에서도 뾰족한 해결방법도 안나와있고, 그냥 커서가 적합하지 않다라고만 되어있어서 많이 해멨습니다. 기존에 컴파일한 Makefile 방식과 에러가 나온 부분의 소스는 아래와 같았습니다.TARGET = sh CC = gcc PROC = proc LIB = -L$(ORACLE_HOME)/lib -lclntsh -lpthread -ldl -lm -lrt -lodbc MYINC = include/ PROCINC = include=$(ORA..
Pro*C 를 짜던 중 아래와 같은 에러코드를 자꾸 뱉습니다.[ERROR] Insert Execute Failure! SQLCODE : -2122 ERROR MSG : SQL-02122: Invalid OPEN or PREPARE for this database connection 오라클 사이트에서 찾아보면, 아래처럼 해결하라고 나와있습니다.Close the cursor to make it available for this connection or use a different cursor for this connection. 대충해석해보자면, 현재 세션이 사용하고 있는 커서를 닫거나, 다른 커서를 사용하세요. 라고 되어있습니다. 데이터베이스를 재구동 해봐도 마찬가지로 발생합니다.SID 별 열려있는 커서를..
ORACLE 에서는 계층데이터를 위해 CONNECT BY 절을 지원합니다. CONNECT BY 구성 CONNECT BY 는 아래의 3개의 구문으로 구성됩니다. 구문 설명 WHERE 데이터를 가져온 뒤 마지막으로 조건절에 맞게 정리 START WITH 어떤 데이터로 계층구조를 지정하는지 지정 CONNECT BY 각 행들의 연결 관계를 설정 * START WITH 는 가장 처음에 데이터를 거르는 플랜을 타게 되고, 따라서 이 컬럼에는 인덱스가 걸려있어야 성능을 보장받습니다.* CONNECT BY 절의 결과에는 LEVEL 이라는 컬럼이 있으며, 이는 계층의 깊이를 의미합니다. CONNECT BY 사용하기 먼저 EMP 테이블에 데이터가 아래와 같이 있습니다.SQL> SELECT * FROM EMP; EMPNO ..
ORACLE 의 SQL 에서는 사용자와의 편리성을 위해 명령어들을 제공합니다. 아래는, 제가 자주쓰는 명령어들 입니다. 옵션 설명 CONN 다른계정으로 접속 ! 리눅스의 명령어를 실행 @파일 파일의 쿼리문을 수행 SET LINESIZE 한 라인에 출력되는 데이터 길이를 지정 SET PAGESIZE 한 페이지에 출력되는 레코드 수를 지정 l 혹은 ; 방금 수행한 쿼리를 출력 ( 소문자 L ) / 방금 수행한 쿼리를 수행 ED 방금 수행한 쿼리를 수정 SET TIMING ON 쿼리 수행에 걸린 시간을 출력 SET LINESIZE 를 1000 으로 설정한 후SQL> select * from emp; EMPNO ENAME JOB MGR ---------- ------------------------------ ..