![]()
데이터베이스 엔진 아키텍처전형적인 데이터베이스의 아키텍처 ( SQL Server 아키텍처도 포함 ) 1. 사용자가 쿼리를 요청하면, 쿼리 최적화기(Query Optimizer)가 요청을 받아 효율적인 수행 계획을 수립합니다.2. 실행 계획을 수립하면 관계 연산자(Relational Operator)가 질의를 단계적으로 수행합니다.3. 질의가 수행되는 각각의 절차에서, 파일 관리자(File Manager)는 파일 내의 페이지를 추적/감시하고 페이지의 정보를 조직합니다.4. 파일 매니저가 조직한 페이지 정보를 필요에 따라 메모리로 가져옵니다.5. 디스크 매니저(Disk Manager)는 페이지를 할당하고 반납하며, 디스크에 기록하는 작업을 수행합니다. SQL Server 의 계층 아키텍처 계층 설명 프로토콜..
![]()
CROSS APPLY 란, 그리고 OUTER APPLY 란table-valued expression 이 사용가능한 조인 방법을 의미합니다. table-valued expression 은 함수에서 RETURN 타입이 테이블 형태인 경우를 의미합니다. 테스트는 아래의 2개 테이블과 1개의 함수로 진행해 보겠습니다.함수의 내용을 보게되면 결국 매개인자로 테이블의 데이터를 반환한다 라는 것을 확인할 수 있습니다.CREATE TABLE FIRST_TABLE (C1 INT, C2 INT)INSERT INTO FIRST_TABLE VALUES (1, 1), (2, 2), (3, 3), (4, 4), (5, 5)GO CREATE TABLE SECOND_TABLE (C1 INT, C2 INT)INSERT INTO SEC..
![]()
SQL Server 에서 권한에 관련하여 GRANT, REVOKE, DENY 구문을 지원합니다. 각 구문은 다음과 같은 특성을 지닙니다.GRANT 는 유저에 개체에 대한 권한을 허용DENY 는 유저에 개체에 대한 권한을 차단REVOKE 는 유저에 부여된 권한을 회수하는 GRANT 도 DENY 도 아닌 상태 GRANT 가 부여되지 않으면 권한에 대한 허용이 없다고 판단하고 작업을 할 수 없습니다.즉, GRANT 가 부여된 권한을 REVOKE 하면 유저는 해당 개체에 대해 작업을 할 수 없습니다. 그렇다면 REVOKE 와 DENY 의 차이점은 무엇일까? REVOKE 와 DENY 가 차이가 없을 경우SCHEMA1 에 대해서 SELECT 권한이 부여되었다고 가정합니다. 이 SCHEMA1 에 대해서 SELECT ..
![]()
SQL Server 는 정렬을 위한 수많은 데이터베이스 언어 셋을 지원하고 있습니다. SELECT * FROM sys.fn_helpcollations() 를 수행하면 지원하는 언어를 볼 수 있습니다.이 중에서 이번에는 Korean 으로 시작되는 정렬 문자열에 대해 알아보겠습니다. Korean_90/100/Wansung 로도 나눠지지만 저희는 Wansung 에 초점을 맞춰서 알아보겠습니다.Wansung 은 완성이란 뜻입니다. (사람의 이름이거나 그렇지 않습니다.ㅎㅎ) Korean_Wansung 의 언어 정렬SELECT name FROM sys.fn_helpcollations() WHERE NAME LIKE 'Korean_Wansung%' 위 쿼리로 검색하면 아래와 같은 값을 얻을 수 있습니다. * 로 쓰면..
다수의 데이터 파일과는 다르게 다수의 로그파일은 성능이익에 전혀 영향을 미치지 않습니다. 트랜잭션 로그파일은 시간순으로 순차적으로 작성되어야 하며,따라서 SQL Server는 리두 로그 파일에 대해 I/O 작업을 병렬처리 할 수 없습니다. 만약 두번째 로그 파일이 사용하게 되는 경우는 첫 번째 로그 파일이 가득 차서 더이상 사용할 수 없게 되는 경우를 나타낼 것입니다. 따라서 저는 아래와 같은 방법이 더 좋다고 생각합니다. 하나의 큰 로그 파일을 사용하자1. 서비스 오픈 전 테스트를 진행하여 로그파일이 어느 사이즈까지 증가하는지를 산정2. 산정한 사이즈 량보다 충분한 여유공간이 있는 RAID10 디스크를 준비3. 해당 디스크에 로그파일의 경로를 설정4. 주기적으로 로그 축소 작업을 진행 추가적으로 FIL..
![]()
먼저 쿼리 하나를 보겠습니다. CREATE DATABASE [SampleDB] ON PRIMARY -- Primary Group( NAME = 'SampleDB_01', -- Primary Group 의 파일1 FILENAME = 'C:\Data\SampleDB_01.mdf', SIZE = 5MB, MAXSIZE = UNLIMITED, FILEGROWTH = 1MB ),( NAME = 'SampleDB_02', -- Primary Group 의 파일2 FILENAME = 'D:\Data\SampleDB_02.mdf', SIZE = 5MB, MAXSIZE = UNLIMITED, FILEGROWTH = 1MB ), FILEGROUP [SECONDARY] -- Secondary Group( NAME = 'Sa..
ORACLE 에서 출력된 데이터로 테이블 생성하기ORACLE 에서는 CREATE TABLE AS SELECT * 문으로 테이블을 생성할 수 있습니다.* 대신 컬럼을 지정할 수도 있습니다.CREATE TABLE NEW_TABLE AS SELECT C1, C2 FROM OLD_TABLE ; SQL Server 에서 출력된 데이터로 테이블 생성하기SQL Server 에서는 SELECT * INFO FROM 문으로 테이블을 생성할 수 있습니다.* 대신 컬럼을 지정할 수도 있습니다.SELECT C1, C2 INTO NEW_TABLE FROM OLD_TABLE ; 새로 생성되는 테이블들은 기존의 제약사항을 가지고 있지 않습니다.
![]()
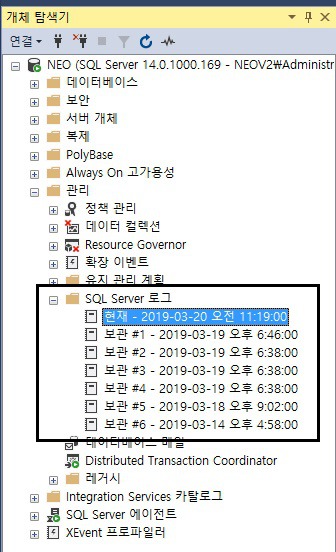
MSSQL 은 SQL Server 로그를 확인할 수 있는 sp_readerrorlog 시스템 프로시저를 지원합니다.기본적으로 sp_readerrorlog 를 수행하면, 가장 최신 로그 파일의 모든 내용을 출력합니다. 추가적으로 sp_readerrorlog 에 옵션을 부여할 수 있는데,sp_readerrorlog @p1, @p2, @p3 와 같이 쓸 수 있습니다.@p1 은 파일 로그 시퀀스@p2 는 1과 2가 있는데 1 은 SQL Server 로그, 2 는 SQL Server 에이전트 로그@p3 은 찾기를 원하는 문자열 입니다. 문자열은 여러개로 구성될 수 있으며 and 연산자로 구성됩니다. xp_readerrorlog 는 추가적인 옵션을 부여할 수가 있습니다.xp_readerrorlog @p1, @p2,..
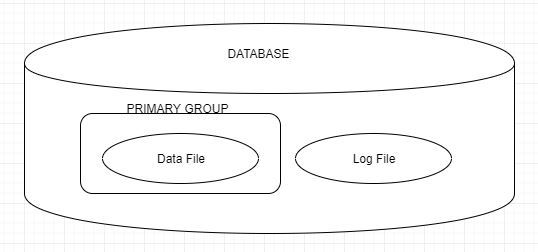
MS-SQL 에는 파일 그룹이라는 개념이 있습니다. 논리적인 관점으로 특정 데이터베이스에는 PRIMARY 라는 하나의 기본 그룹이 있고 그 안에 하나의 데이터 파일이 있습니다.그리고 트랜잭션 로그 파일도 있는데, 이는 파일 그룹과 관련이 없습니다.즉, 파일 2개와 그룹 1개인 최소한의 구조로 구성되며, 기본적인 파일 그룹 PRIMARY 의 이름은 변경하거나 제거할 수 없습니다. 물리적인 관점에서 본다면 생성된 데이터베이스는 하나의 하드디스크에 데이터 파일과 트랜잭션 로그 파일로 구성됩니다.하지만 동시다발적으로 데이터가 대규모로 입력될 때 하나의 디스크에 동시에 접근한다면 성능은 느려질 수 밖에 없습니다.따라서 데이터 파일과 트랜잭션 로그 파일은 기본적으로 서로 다른 디스크에 분리해서 관리해야 합니다. 하..
MS-SQL 에서 데이터베이스는 최소한 다음 2개의 파일을 소유하고 있어야 합니다. 첫 번째는 주 데이터 파일(Primary Data File), 확장명이 .mdf 로 실제 데이터가 저장되는 공간입니다.두 번째는 트랜잭션 로그 파일(Transaction Log File), 확장명이 .ldf 로 데이터베이스 복구에 사용되는 트랜잭션 로그가 저정되는 공간입니다. 그리고 추가로 가질 수 있는 파일이 있습니다.보조 데이터 파일(Secondary Data File)로 확장명은 .ndf, 추가적으로 데이터가 저장되는 공간입니다. 그렇다면 보조 데이터 파일은 무엇을 하는가? 입니다.데이터파일에 저장 시 하나의 파일그룹을 사용할 때 보다 좋은 성능을 낼 수 있기 때문에 보조데이터 파일을 사용합니다.예를 들어서 자주 접..