집합연산자 두 개 이상의 테이블에서 조인을 사용하지 않고 연관된 데이터를 조회하는 방법 중에 또 다른 방법이 있는데 집합연산자를 사용하는 방법입니다.집합 연산자는 여러 개의 질의의 결과를 연결하여 하나로 결합하는 방식을 사용합니다.집합 연산자를 사용하기 위해서는 SELECT 절의 컬럼 수가 동일하고, 동일 위치에 존재하는 컬럼의 데이터 타입이 상호 호환 가능해야 합니다. 집합 연산자의 종류 집합 연산자 연산자 의미 UNION 여러 개의 SQL 문의 결과에 대한 합집합으로 결과에서 모든 중복된 행은 하나의 행으로 출력 UNION ALL 여러 개의 SQL 문의 결과에 대한 합집합으로 중복된 행도 그대로 결과로 표시 INTERSECT 여러 개의 SQL 문의 결과에 대한 교집합으로 중복된 행은 하나의 행으로 출..
2018/11
crontab command not found 에러현상 crontab 에 등록하지 않고 터미널에서 수행 시 정상적으로 되던 스크립트가 crontab 에만 등록하면 오류가 발생하였습니다. 문제의 원인을 찾고자 사용자 계정의 로그(메일)를 확인하니 아래와 같이 에러가 발생했습니다.$ cat /var/spool/mail/sh ... /home/sh/goldilocks_backup.sh: line 199: gsqlnet: command not found crontab command not found 에러원인 crontab 에 등록되어 있다고는 하지만, 사용자 계정에서 실행하였으므로당연히 사용자의 환경변수를 물고 올라갈거라고 생각했는데 crontab 에서 환경변수를 출력하니 전부 빈 값이었습니다.환경변수가 잡혀있..

CHAR 와 VARCHAR CHAR 고정길이 문자열 타입으로 만약 타입의 크기만큼의 데이터가 들어오지 않은경우 이후의 공간을 스페이스로 채워넣습니다.고정길이 문자열이기 때문에 헤더에는 레코드의 길이에 대한 정보가 들어있지 않습니다. VARCHAR 가변길이 문자열 타입으로 타입의 크기만큼의 데이터가 들어오지 않더라도 이후의 공간을 스페이스로 채워넣지 않습니다.가변길이 문자열이기 때문에 헤더에는 레코드의 길이에 대한 정보가 포함되어야 합니다. 예를들어 CHAR(5) 와 VARCHAR(5) 에 데이터 ABC 가 들어오는 경우 아래처럼 저장이 됩니다. CHAR 와 VARCHAR 의 차이점 그렇다면 실제 쿼리에서 조회를 하게 되면 어떻게 될까요?GOLDILOCKS 데이터베이스에서 테스트를 진행해보았습니다. ORA..
스택 한쪽 끝에서만 자료를 넣거나 뺄 수 있는 선형 구조 LIFO ( Last In First Out ) 구조로 저장되는 형식을 말합니다.자료를 넣는 것을 Push, 자료를 꺼내는 것을 Pop 이라고 합니다.꺼내지는 자료는 가장 최근에 보관된 자료부터 나오게 됩니다. 스택의 함수 S.top() 스택의 가장 윗 데이터를 넘겨줍니다.만약에 비었다면 이 연산은 정의불가의 상태입니다. S.pop() 스택의 가장 윗 데이터를 넘겨주고 해당 데이터를 스택에서 삭제합니다.스택이 비었다면 연산은 정의불가 상태입니다. S.push() 스택의 가장 윗 데이터로 top 이 가리키는 자리 위에 메모리를 생성한 후 데이터를 넣습니다. S.empty() 스택이 비어있다면 참, 그렇지 않다면 거짓을 반환합니다. 스택의 코드 pop..
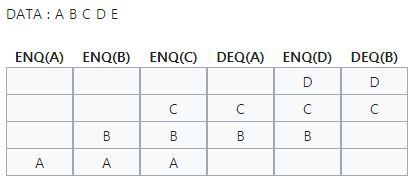
큐 먼저 집어 넣은 데이터가 먼저 나오는 FIFO ( First In First Out ) 구조로 저장되는 형식을 말합니다.프린터의 출력, 키보드 입력 등 데이터가 입력된 시간 순서대로 처리해야 할 필요가 있는 상황에서 사용됩니다. 큐는 Put ( 삽입 ), Get ( 삭제 ) 를 이용하여 구현됩니다.Put 은 큐에 자료를 넣는 것을, Get 은 큐에서 자료를 꺼내는 것을 의미합니다.Front 와 Rear 은 데이터의 위치를 가르키며, Front 는 데이터를 Get 할 수 있는 위치, Rear 는 데이터를 Put 할 수 있는 위치를 의미합니다.큐가 가득차서 자료를 더이상 넣을 수 없는 경우를 오버플로우, 큐가 비어있어 자료를 꺼낼수 없는 경우를 언더플로우라고 합니다. 큐의 종류 및 작동방식 선형과 환형이..
삽입정렬 자료 배열의 모든 요소를 앞에서부터 차례대로 이미 정렬된 배열 부분과 비교하여, 자신의 위치를 찾아 삽입하는 방식입니다.배열이 길어질수록 효율이 떨어지지만, 구현이 간단합니다.시간복잡도는 O(n^2) 입니다. 삽입정렬 알고리즘 1. 두 번째 원소를 부분 리스트에서 적절한 위치에 삽입합니다.2. 세 번째 원소를 부분 리스트에서 적절한 위치에 삽입합니다.3. 위의 작업을 정렬이 끝날때까지 반복합니다. 삽입정렬 예제 25 를 앞의 리스트와 비교하여 적절한 위치에 삽입합니다.3125122211 253112221112 를 앞의 리스트와 비교하여 적절한 위치에 삽입합니다.2531122211 122531221122 를 앞의 리스트와 비교하여 적절한 위치에 삽입합니다.1225312211 122225311111..
선택정렬 첫번째 항목부터 최소값을 탐색하여 교환하며 정렬하는 방식입니다.n 개의 주어진 리스트를 정렬하는데 O(n^2) 만큼의 시간이 걸립니다. 선택정렬의 알고리즘 1. 주어진 리스트 중에 최소값을 찾습니다.2. 찾은 값을 맨 앞에 위치한 값과 교체합니다.3. 맨 처음 위치를 뺀 나머지를 같은 방법으로 교체합니다. 선택정렬의 예제 가장 작은값(0)을 찾은 뒤 가장 좌측값(9)와 교환합니다.9,1,6,8,4,3,2,0 0,1,6,8,4,3,2,9가장 작은 값(1) 을 찾은 뒤 가장 좌측에서 다음번의 위치와 교환합니다. (여기에서는 같은 값이므로 교환되지 않습니다.)0,1,6,8,4,3,2,9가장 작은 값(2) 를 찾은 뒤 그 다음의 좌측값(6)과 교환합니다.0,1,6,8,4,3,2,9 0,1,2,8,4,3..
버블정렬 두 인접한 원소를 검사하여 정렬하는 방법입니다.시간 복잡도가 O(n^2) 로 느리지만, 코드가 단순하여 사용하기 편리합니다. 버블정렬의 알고리즘 1. 앞에서 두 개의 원소를 비교합니다.2. 앞의 원소가 뒤의 원소보다 큰 경우 변경합니다. 작은 경우에는 변경하지 않습니다.3. 다음 위치의 두 개의 원소를 비교합니다.4. 위치의 끝까지 간 경우 다시 처음부터 비교합니다. 버블정렬의 예제 앞의 55 와 07 을 비교합니다. 07 이 55 보다 작으므로 위치를 변경합니다.55 07 78 12 42 07 55 78 12 4255 와 78 을 비교합니다. 55 가 작으므로 위치를 변경하지 않습니다.78 과 12 를 비교합니다. 12 가 작으므로 위치를 변경합니다.07 55 78 12 42 07 55 78 ..
퀵 정렬 찰스 앤터니 리처드 호어가 개발한 정렬 알고리즘입니다.n 개의 데이터를 정렬할 때 최악의 경우 O(n^2) 번의 비교를 수행하고 평균적으로 O(n log n)번의 비교를 수행합니다.정렬되지 않은 데이터들에 대해서 속도와 효율성이 가장 좋다고 할 수 있는 정렬 방식입니다. 퀵 정렬의 알고리즘 1. 리스트 가운데에서 하나의 원소를 선택합니다. 이 원소를 피벗 이라고 칭합니다.2. 피벗 앞에는 피벗보다 값이 작은 모든 원소들이 오고, 피벗 뒤에는 피벗보다 값이 큰 모든 원소들이 오도록 피벗을 기준으로 리스트를 둘로 나눕니다. 이렇게 리스트를 둘로 나누는 것을 분할이라고 합니다. 분할은 마친 뒤에 피벗은 더이상 움직이지 않습니다.3. 분할된 두 개의 작은 리스트에 대해 재귀적으로 이 과정을 반복합니다...

NL Join 프로그래밍에서 사용하는 중첩된 반복문과 유사한 방식으로 조인을 수행합니다.선행 테이블의 조건을 만족하는 행을 추출하여 후행 테이블을 읽으면서 조인을 수행합니다. 이 작업은 선행 테이블의 조건을 만족하는 모든 행의 수만큼 반복 수행합니다.따라서 결과행의 수가 적은 테이블을 선행 테이블로 선택하는 것이 좋습니다. 작업 방법1. 선행 테이블에서 주어진 조건을 만족하는 행을 찾음2. 선행 테이블의 조인 키 값을 가지고 후행 테이블에서 조인 수행3. 선행 테이블의 조건을 만족하는 모든 행에 대해 1번 작업 반복 수행 그림으로 좀더 세분화합니다. 1. 선행 테이블에서 조건을 만족하는 첫 번째 행을 찾음2. 선행 테이블의 조인 키를 가지고 후행 테이블에 조인 키가 존재하는지 찾음3. 후행 테이블의 인덱..