GOLDILOCKS DBMS 를 기준으로 설명되며, 이는 다른 DBMS 또한 동일합니다.
T1 테이블에 다수개의 필드가 있고, 데이터가 많이 있는 상황입니다.
gSQL> SELECT * FROM T1 LIMIT 10; DESCRIPTION LOGICAL_ADDR REF_COUNT SPIN_LOCK WAIT_COUNT X_LOCK_SEQ CURRENT_MODE CAS_MISS_COUNT ----------------------------- --------------- --------- --------- ---------- ---------- ------------ -------------- PCH ( TBS:4, PAGE:0, TYPE:9 ) 562949991497728 0 0 0 14 INITIAL 0 PCH ( TBS:4, PAGE:1, TYPE:9 ) 562949991497856 0 0 0 0 INITIAL 0 PCH ( TBS:4, PAGE:2, TYPE:9 ) 562949991497984 0 0 0 0 INITIAL 0 PCH ( TBS:4, PAGE:3, TYPE:9 ) 562949991498112 0 0 0 0 INITIAL 0 PCH ( TBS:4, PAGE:4, TYPE:9 ) 562949991498240 0 0 0 0 INITIAL 0 PCH ( TBS:4, PAGE:5, TYPE:9 ) 562949991498368 0 0 0 0 INITIAL 0 PCH ( TBS:4, PAGE:6, TYPE:9 ) 562949991498496 0 0 0 0 INITIAL 0 PCH ( TBS:4, PAGE:7, TYPE:9 ) 562949991498624 0 0 0 0 INITIAL 0 PCH ( TBS:4, PAGE:8, TYPE:9 ) 562949991498752 0 0 0 0 INITIAL 0 PCH ( TBS:4, PAGE:9, TYPE:9 ) 562949991498880 0 0 0 0 INITIAL 0 ... 202904 rows selected.
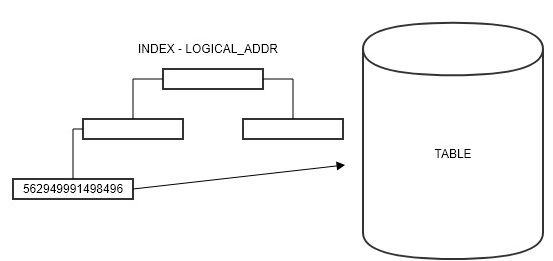
LOGICAL_ADDR 컬럼을 기반으로 REF_COUNT 를 추출하려고 할 때,
컬럼 지향 데이터베이스가 아닌경우 데이터 블록은 레코드의 모든 필드를 접근하므로 성능에서 떨어지게 됩니다.
인덱스를 사용하는 경우 인덱스 검색으로 LOGICAL_ADDR 컬럼 해당 레코드의 물리 주소를 추출한 후,
이 주소를 기반으로 테이블의 REF_COUNT 컬럼에 접근해 레코드를 추출하게 됩니다.

그런데 만약, 인덱스에 LOGICAL_ADDR 과 REF_COUNT 가 포함되어 있다면, 테이블에 접근할 필요가 없어지게 됩니다.

이런 동작을 '커버링 인덱스' 라고 부르며, 인덱스 접근만으로 결과를 얻을 수 있게 됩니다.
예를 들어 보겠습니다.
LOGICAL_ADDR 컬럼을 조건으로 REF_COUNT 컬럼을 추출하려고 합니다.
인덱스에 LOGICAL_ADDR 만 있는 경우
LOGICAL_ADDR 인덱스에 접근하여 해당 데이터의 물리적 주소를 추출한 후, 테이블에 접근하여 REF_COUNT 를 읽어옵니다.
gSQL> CREATE INDEX IDX_T1 ON T1 (LOGICAL_ADDR);
gSQL> EXPLAIN PLAN ONLY
2 SELECT REF_COUNT
3 FROM T1
4 WHERE LOGICAL_ADDR = '562949991498496';
>>> start print plan
< Execution Plan >
==================================================================================================
| IDX | NODE DESCRIPTION | ROWS |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | INDEX ACCESS ("T1", "IDX_T1") [CLONED] | 0 |
==================================================================================================
1 - READ INDEX COLUMNS : LOGICAL_ADDR
READ TABLE COLUMNS : REF_COUNT
MIN RANGE : LOGICAL_ADDR = '562949991498496'
MAX RANGE : LOGICAL_ADDR = '562949991498496'
<<< end print plan인덱스에 LOGICAL_ADDR, REF_COUNT 가 있는 경우
LOGICAL_ADDR 과 REF_COUNT 의 복합 인덱스에 접근하여, 테이블까지 접근하지 않고 인덱스에서만 데이터 결과를 추출합니다.
gSQL> CREATE INDEX IDX_T2 ON T1 (LOGICAL_ADDR, REF_COUNT);
gSQL> EXPLAIN PLAN ONLY
2 SELECT REF_COUNT
3 FROM T1
4 WHERE LOGICAL_ADDR = '562949991498496';
>>> start print plan
< Execution Plan >
==================================================================================================
| IDX | NODE DESCRIPTION | ROWS |
--------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | |
| 1 | INDEX ACCESS ("T1", "IDX_T2") [CLONED] | 0 |
==================================================================================================
1 - READ INDEX COLUMNS : LOGICAL_ADDR, REF_COUNT
MIN RANGE : LOGICAL_ADDR = '562949991498496'
MAX RANGE : LOGICAL_ADDR = '562949991498496'
<<< end print plan그렇다면, 모든 조회쿼리의 조건과 추출 컬럼에 인덱스를 걸면될까요?
너무 많은 인덱스는 관리 비용 증가, DML 의 성능 저하 등의 문제를 야기할 수 있습니다. :-)
'Database > 개념' 카테고리의 다른 글
| [DATABASE] 데이터 모델의 표기법인 ERD 란? (0) | 2018.10.21 |
|---|---|
| [DATABASE] 데이터 모델링, 데이터 독립성 이란? (0) | 2018.10.21 |
| [DATABASE] 데이터베이스 스캔방식 설정으로 쿼리 응답속도 높이는 방법 알아보기 (0) | 2018.08.17 |
| [DATABASE] 데이터베이스 정규화 1NF, 2NF, 3NF, BCNF, 4NF, 5NF 알아보기 (1) | 2018.06.18 |
| [DATABASE] 데이터베이스 OLAP 과 OLTP 의 차이점, 그리고 DW 의미 알아보기 (0) | 2018.05.26 |